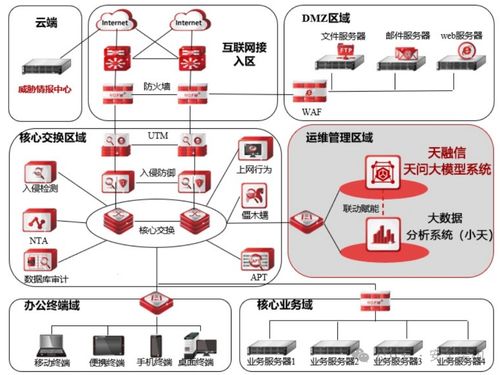
近日,黑莓公司正式發布了其創新的軟件網絡安全產品——Jarvis,該產品旨在高效完成車載軟件的漏洞掃描,為汽車行業提供更強大的網絡與信息安全保障。
隨著汽車智能化與網聯化程度的不斷提升,車載軟件的復雜性和互聯性日益增強,隨之而來的網絡安全風險也愈發嚴峻。車載軟件一旦存在漏洞,可能被惡意攻擊者利用,導致車輛控制權被篡改、用戶數據泄露甚至行車安全事故。傳統的漏洞掃描方法往往耗時較長,難以滿足現代汽車快速迭代的開發需求。
Jarvis的推出正是針對這一痛點。該產品采用先進的靜態分析與動態測試技術,能夠對車載軟件代碼進行深度掃描,快速識別潛在的安全漏洞,如緩沖區溢出、注入攻擊、權限提升等常見威脅。據黑莓介紹,Jarvis可以在幾分鐘內完成對大規模軟件系統的全面檢查,效率遠超傳統手動或半自動化掃描工具。這不僅縮短了開發周期,還顯著降低了因漏洞未被及時發現而引發的安全風險。
Jarvis還具備高度的可擴展性和兼容性,能夠適配多種車載操作系統和硬件平臺,包括QNX、Android Automotive等主流環境。用戶可以通過云端或本地部署靈活使用該服務,并根據需要定制掃描策略和報告格式。黑莓強調,Jarvis不僅適用于汽車制造商,還可廣泛應用于供應鏈中的軟件供應商和第三方測試機構,幫助構建端到端的車輛網絡安全生態。
在網絡與信息安全軟件開發領域,Jarvis的推出標志著黑莓在汽車網絡安全解決方案上的進一步深化。該公司憑借其在嵌入式系統和安全技術方面的積累,為智能網聯汽車提供了從硬件到軟件的全方位保護。未來,隨著自動駕駛和車聯網技術的普及,類似Jarvis這樣的高效安全工具將成為行業標準配置。
黑莓Jarvis的發布為車載軟件安全樹立了新的標桿。通過快速、準確的漏洞掃描能力,它不僅提升了汽車網絡安全的防護水平,也為整個行業的可持續發展注入了信心。隨著更多企業采用此類先進工具,我們有望看到一個更安全、更可靠的智能交通新時代。